[database]
type = postgres
host = ipeseserv3.epfl.ch
port = 12345
database = QBuildings-Suisse
username = students
password = students_project3 Tutorial
Now that we have a good picture of what is GBuildings, this part should help you understand how to use it.
3.1 Visualisation of the data
Most of users do not need to modify the database, but only to use the data contained. To do so, a reader user should be used.
They are several ways to visualise the data:
- QGIS: useful to have a geographical representation of the data
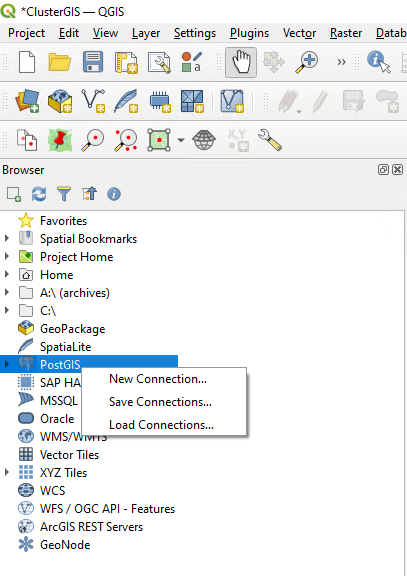
Open the Browser panel and connect to PostGIS by opening a new connection:
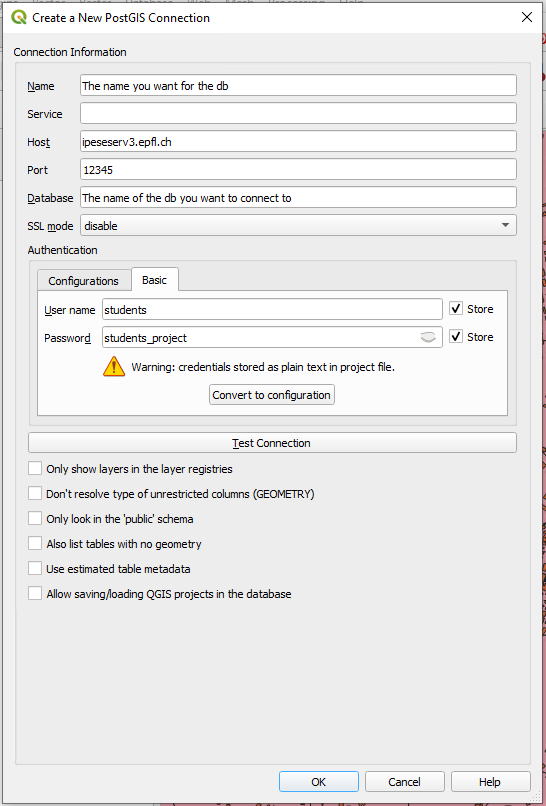
Enter the credentials:
- Pycharm: useful to have a quick access when you code
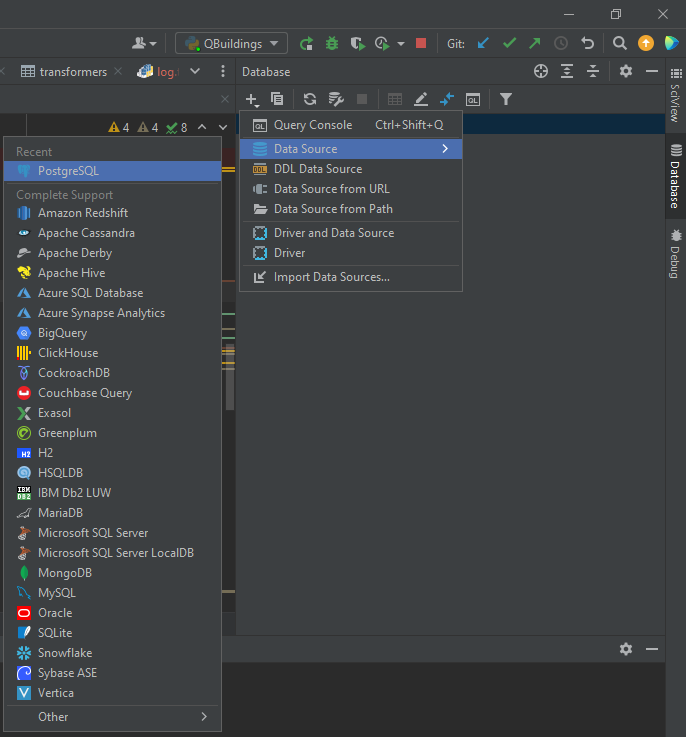
Open the Database panel and add a connection and find PostgreSQL in the Data Source list:
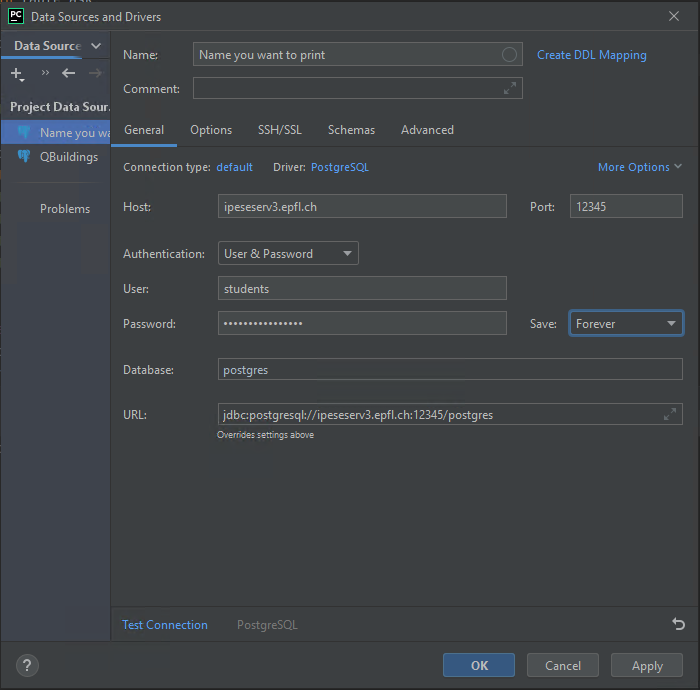
Enter your credentials:
- For Visual Studio Code users, follow the instructions from this extension
3.2 Accessing the data in code
For some tools, it is useful to get the data in a GeoDataframe from pandas. Two things are needed to do so:
- A .ini file that contains the credentials to access the database.
- sqlalchemy package to connect to the database.
from sqlalchemy import create_engine, MetaData, select
import configparser
def establish_connection(db, schema):
"""
:param db: Name of the database to which we want to connect - Suisse, Geneva, ...
:param schema: Name of the schema you want to connect to - Aggregated, Processed, Smoothed
"""
# Database connection
file_ini = your_own_path + "/" + db + ".ini"
project = configparser.ConfigParser()
project.read(file_ini)
# Database
db_schema = schema
try:
db_engine_str = 'postgresql+psycopg2://{}:{}@{}:{}/{}'.format(project['database']['username'],
project['database']['password'],
project['database']['host'],
project['database']['port'],
project['database']['database'])
db_engine = create_engine(db_engine_str)
connection = db_engine.connect()
print('Connected to database')
except:
print('Cannot connect to database engine')
if 'database' in project:
print('\thost: {}\n\tport: {}\n\tdatabase: {}\n\tusername: {}'.format(
project['database']['host'],
project['database']['port'],
project['database']['database'],
project['database']['username']))
metadata = MetaData(bind=db_engine)
if isinstance(db_schema, list):
for schema in db_schema:
metadata.reflect(schema=schema)
else:
metadata.reflect(schema=schema)
return db_engine, connection, metadataOnce the tables are reflected using establish_connection(db , schema), queries can be done on the reflection. However, with the students user, only select queries can be done.
The most simple select query is the following one:
import sqlalchemy as sa
from sqlalchemy.dialects import postgresql
import geopandas as gpd
db_schema = "Processed" # Should be the schema you want to access
table_name = "buildings" # The table you want to access
selectQuery = sa.select(tables[db_schema + '.' + table_name])
data = gpd.read_postgis(selectQuery.compile(dialect=postgresql.dialect()), con=db_engine, geom_col='geometry').fillna(np.nan)It returns a GeoDataframe with all the rows from the database. However, read_postgis is slow so in case you have a large set of data, you may prefer to fetch the rows not all at once.
selectQuery = sa.select(tables[db_schema + '.' + table_name])
order = connection.execute(selectQuery.compile(dialect=postgresql.dialect()))
flag = True
results = []
while flag:
partial_results = order.fetchmany(1000)
if not partial_results:
flag = False
else:
results += partial_results
data = pd.DataFrame(results)
geom = gpd.GeoSeries(to_shape(row) for row in data['geometry'])
data = gpd.GeoDataFrame(data, geometry=geom)Finally, if needed a condition can be added on the row to be selected.
columns_with_criteria = 'id' # The column on which there is the selection criteria
selection = eval(tables[db_schema + '.' + table_name] + ".columns." + columns_with_criteria)
criteria = 10 # The value on which the selection has to be made
selectQuery = sa.select(tables[db_schema + '.' + table_name]) \
.where(selection == criteria)If the selection has to be done on more than one criteria, then a join query should be done. It is highly recommended to perform join queries on keys (primary key or foreign key) to fasten the result.
Additional options on select are ORDER BY, GROUP BY and HAVING. It is also much faster to do it in SQL than using pandas.
3.3 Modifying the data in code
For most of the users, it is highly discouraged to modify the QBuildings-Suisse db, which is the one used by everybody. Most likely, the easiest thing to do is to create a database for the area on which you are going to work. To do so, the easiest way is to select the data from QBuildings-Suisse that cross the area and insert them into a new db.
The first step is to create your own database. This should be done by a user that has the global access to the databases server. In practice, for the moment, this means contact Joseph Loustau on Mattermost. The following information should be provided:
- username
- password if you have a preferred one (otherwise, one would be generated for you)
- Name of the database
- Any additional fields or tables
You will have a personal user with full grants to your own db and a db with the same tables as the ones in QBuildings-Suisse but empty. To fill it, either the right data from Suisse should be extracted, either the QBuildings repository is used.
3.4 Extract data from QBuildings-Suisse
The copy_by_mask function will copy the data from Suisse into your db, according to the geographical mask used as a filter.
import psycopg2
from geoalchemy2 import Geometry
from sqlalchemy.dialects import postgresql
import geopandas as gpd
import pandas as pd
from timeit import default_timer as timer
from geoalchemy2.shape import to_shape
def copy_by_mask(db_from, db_to, schema_to_copy, mask):
"""
:param db_from: dictionary with the information of db from which the data have to be imported
:param db_to: dictionary with the information of db from which the data have to be exported
:param mask: a geopackage that delimits the area of interest
:return:
"""
def insert_query(db_to, t, selection_query, nrows):
connect_to = db_to['engine'].connect()
order = connection.execute(selection_query.compile(dialect=postgresql.dialect()))
nrows = connection.execute(nrows.compile(dialect=postgresql.dialect())).fetchone().count
flag = 0
divider, remain = divmod(nrows, 100000)
while flag < divider:
partial_results = order.fetchmany(100000)
if not partial_results:
flag = divider + 1
else:
df_inter = pd.DataFrame(partial_results)
geom = gpd.GeoSeries(to_shape(row) for row in df_inter['geometry'])
df_inter = gpd.GeoDataFrame(df_inter, geometry=geom, crs='EPSG:2056') # TODO: get the CRS from SQL
df_inter.to_postgis(name=re.split("\.", t)[1], if_exists='append', schema=re.split("\.", t)[0], con=db_to['engine'])
partial_results = order.fetchmany(remain)
if partial_results:
df_inter = pd.DataFrame(partial_results)
geom = gpd.GeoSeries(to_shape(row) for row in df_inter['geometry'])
df_inter = gpd.GeoDataFrame(df_inter, geometry=geom, crs='EPSG:2056')
df_inter.to_postgis(name=re.split("\.", t)[1], if_exists='append', schema=re.split("\.", t)[0], con=db_to['engine'])
connect_to.close()
return
mask = gpd.read_file(filename=mask)
tables = db_from['metadata'].tables
for schema in schema_to_copy:
connection = db_from['engine'].connect()
# Select transformers
print('\nSelect transformers from ' + schema + ' by intersection\n\n')
geom = mask['geometry'].buffer(-150).to_wkb().tolist()[0]
df_transformer = tables[schema + '.' + 'transformers']
transfoQuery = select(df_transformer).where(df_transformer.c.geometry.st_intersects(geom))
nrows = select(func.count(df_transformer.c.id)).where(df_transformer.c.geometry.st_intersects(geom))
ctequery = transfoQuery.cte()
insert_query(db_to, schema + '.' + 'transformers', transfoQuery, nrows)
# Select buildings
start = timer()
print('Select buildings corresponding to the selected transformers')
j = tables[schema + '.' + 'buildings']. \
join(ctequery, tables[schema + '.' + 'buildings'].c.transformer == ctequery.c.id)
df_building = tables[schema + '.' + 'buildings']
buildingQuery = select([df_building]).select_from(j)
nrows = select(func.count(df_building.c.id_building)).select_from(j)
ctequery_build = select([df_building.c.id_building]).select_from(j).cte()
insert_query(db_to, schema + '.' + 'buildings', buildingQuery, nrows)
end = timer()
print('Operation took', end - start)
# Select tables
if schema == 'Aggregated':
tables_to_copy = ['buildings_RegBL', 'roofs', 'facades']
else:
tables_to_copy = ['roofs', 'facades']
for t in tables_to_copy:
print('Select', t, 'according to selected buildings')
start = timer()
j_build = tables[schema + '.' + t].join(ctequery_build, tables[schema + '.' + t].c.id_building
== ctequery_build.c.id_building)
sqlQuery = select([tables[schema + '.' + t]]).select_from(j_build)
nrows = select(func.count(tables[schema + '.' + t].c.id_building)).select_from(j_build)
insert_query(db_to, schema + '.' + t, sqlQuery, nrows)
end = timer()
print('Operation took', end - start, 'for table', t)
connection.close()
return print('Data copied')
if __name__ == '__main__':
schemas = ['Aggregated', 'Processed', 'Smoothed']
db_engine_suisse, metadata_suisse = establish_connection("Suisse", schemas)
db_engine_db, metadata_db = establish_connection("your_db", schemas)
db_from = {'engine': db_engine_suisse,
'metadata': metadata_suisse
}
db_to = {'engine': db_engine_db,
'metadata': metadata_db
}
mask = 'your_perimeter.gpkg'
copy_by_mask(db_from, db_to, schemas, mask)However, Suisse still has some issues and some data are incorrect (pay attention to roof_solar_area_m2 and capita_cap particularly). Those errors are caused by wrong intersections at big scale that may not happen at smaller scale. To generate new data on your area of interest, use the QBuildings repository.
3.4.1 QBuildings repository
The python repository (5 in Figure 1.1) is the repository used to generate the data into the db. The description of what it contains can be found in Section (gbuildings-repository?).
To run it, the user should follow these steps:
Go to the share drive IPESESERV5
- If you are on Windows: \\ipeseserv5\Desktop Share\IPESE-projects\QBuildings in the Windows explorer
- If you are on Mac: Finder > Go > Connect to server > smb://ipeseserv5 > Connect > Desktop Share > IPESE-projects > QBuildings
- Create a folder with the same structure than the one from Suisse,
- Copy the database.ini file that can be retrieve from Suisse model,
- Change the name of the input layers with the corresponding ones from your region. If they are not available, you can pass the national ones but the correct mask of the region of interest. However, this will take longer to compute.
Go to the python repository, open QBuildings.py and pick the options
- db: Name of the db you want to modify
- export_format: Can be among [‘db’, ‘csv’, ‘gpkg’, ‘shp’, ‘geojson’, ‘xls’]
- replace: Erase the existing db
- with_mask: if your area of interest contains more than 10’000 buildings, put True
- export_warning: if True, export the buildings for which an error occurred
- layer: Layer to run among [‘Aggregated’, ‘Processed’, ‘Smoothed’]
- tables: Tables to modify among [‘buildings’, ‘roofs’, ‘facades’, ‘transformers’] , [‘all’] to take them all at once